最近又要开始找房,来上海三年不到已经是第三次搬家,真是居大不易。现在住的房子是在豆瓣小组上找的,豆瓣上个人房源较多,但是豆瓣小组没有对房源信息进行分类,找起来比较费时,索性写了个简单的爬虫,根据关键字来找房。网上也有一些现成的代码实现,想着还是自己实践一下。
Python 新手上路…
获取豆瓣房源小组链接
先搜索一下上海的租房小组

找几个人数较多和活跃度高的小组,进入小组讨论页面,观察 URL 的规律。
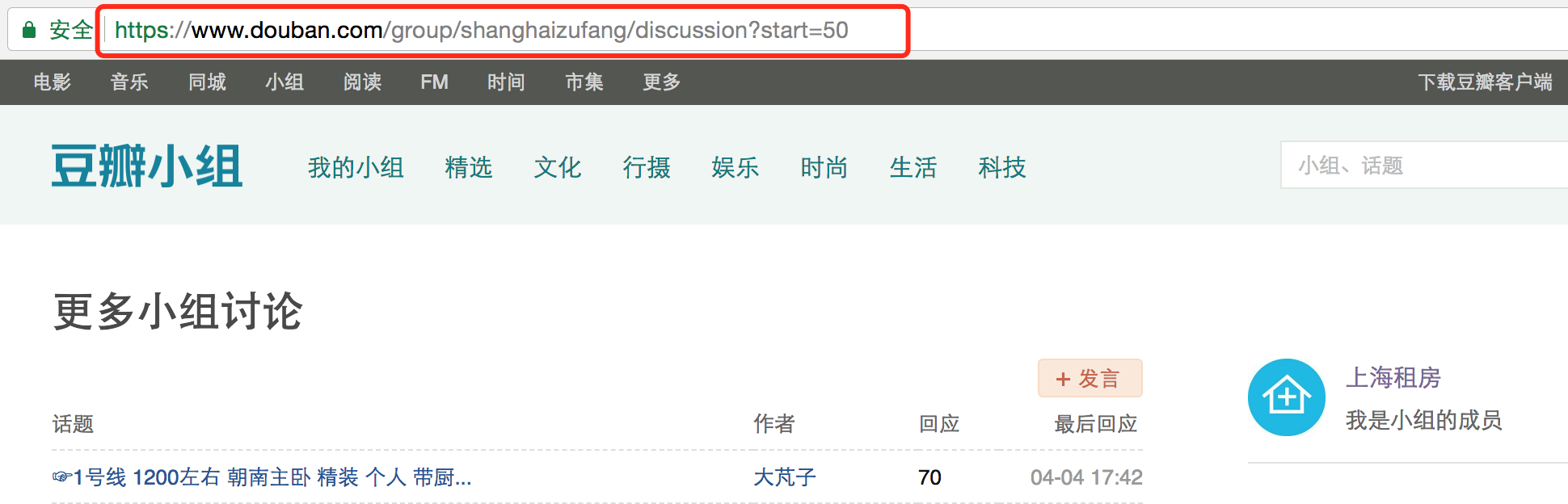

由此可知我们可以通过 https://www.douban.com/group/<组名>/disscussion 来获取不同组的房源帖子信息,我选取了五个小组进行爬取。
In [1]: import os
In [2]: group_list = ['shanghaizufang', 'homeatshanghai', '383972', 'shzf', '251101']
In [3]: index_url = [os.path.join('https://www.douban.com/group', i, 'discussion') for i in group_list]
In [4]: index_url
Out[4]:
['https://www.douban.com/group/shanghaizufang/discussion',
'https://www.douban.com/group/homeatshanghai/discussion',
'https://www.douban.com/group/383972/discussion',
'https://www.douban.com/group/shzf/discussion',
'https://www.douban.com/group/251101/discussion']
资源定位
通过查看页面元素信息,找到每个帖子标题所对应的网页代码。我们可以发现每个房源标题对应的是一个 class 属性为 title 的 td 标记。

使用 BeautifulSoup 尝试获取一下小组讨论中帖子标题网页代码
In [1]: import requests
In [2]: from bs4 import BeautifulSoup
In [3]: url = 'https://www.douban.com/group/shanghaizufang/discussion'
In [4]: headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 '
...: '(KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'}
In [5]: res = requests.get(url, headers=headers)
In [6]: soup = BeautifulSoup(res.text, 'html.parser')
In [7]: title_list = soup.find_all('td', class_='title')
In [8]: for tl in title_list:
...: print(tl)
...:
<td class="title">
<a class="" href="https://www.douban.com/group/topic/114471599/" title="黄浦区临地铁4号13号线单间出租。2300!无中介,可月租!">
黄浦区临地铁4号13号线单间出租。2300!无中介,可...
</a>
</td>
<td class="title">
<a class="" href="https://www.douban.com/group/topic/113810667/" title="——有阳台·房间空间大·低价出租·2260元·正南·电梯房·步行6分钟到7号线·《盒马生鲜·DFC影院·大华锦绣国际》隔壁·锦绣华城2街区">
——有阳台·房间空间大·低价出租·2260元·正南...
</a>
</td>
<td class="title">
<a class="" href="https://www.douban.com/group/topic/111282163/" title="7号线杨高南路___北艾路1200弄超大1室_正南_大飘窗_2790元">
7号线杨高南路___北艾路1200弄超大1室_正南_大飘窗...
</a>
</td>
...
关键字过滤
通过 BeautifulSoup 我们已经成功获取到帖子标题相关网页代码信息,接下来就是匹配我们的关键字并把对应标题的 url 保存下来,这样我们就不用一页页去找房源信息。
In [9]: for tl in title_list:
...: print(tl.a['title'], tl.a['href'])
...:
紧靠漕河泾地铁12号线虹梅路站古美小区精装一室户随时看房 https://www.douban.com/group/topic/114690388/
【性价比最高】【2/4/6/9】世纪大道地铁站口200米内,2018.4.5起三天内【出租】有效 https://www.douban.com/group/topic/114031302/
陆家嘴,2号线东昌路站,精装南北两房一厅,5400元可谈,乳山四村 https://www.douban.com/group/topic/114838496/
7号线30秒___高科西路2111弄(独立阳台_洗漱)2890 https://www.douban.com/group/topic/111749919/
1号线外环路站______主卧朝南、近地铁 https://www.douban.com/group/topic/115006334/
7号线__成山路2388弄(高档小区)__环境美_2090元 https://www.douban.com/group/topic/111343989/
1500元就能租到社区一居室/复式低价火热出租ING https://www.douban.com/group/topic/114031502/
1号线❤️莲花路站❤️朝南+落地窗(4分钟到地铁)___2200¥ https://www.douban.com/group/topic/115010633/
工作调动2469号线德平路地铁站两房!价格可刀 https://www.douban.com/group/topic/114668639/
2号线 淞虹路站 通协小区 朝南主卧带飘窗 随时入住 精装全配 可做饭 凌空首选随时入住先到先得 2700/月 https://www.douban.com/group/topic/114638949/
3号线铁力路站,实体墙一室带独立卫生间,可以做饭,出租1900元。 https://www.douban.com/group/topic/115000070/
1号线莲花路站_____步行2分钟(西班牙名园小区) https://www.douban.com/group/topic/115009200/
—落地大阳台·2780元·豪装—海归首选房—敞亮的大房子《陆家嘴·锦绣里》高档小区—电梯房 https://www.douban.com/group/topic/113808306/
静安高荣小区朝南带阳台主卧出租<限女生>3100/月,直接和房东签合同 https://www.douban.com/group/topic/114799989/
1号线❤️外环路站【主卧独卫】地铁口__ 上海阳城小区 https://www.douban.com/group/topic/115008659/
五角场附近主卧出租,市光路70弄小区,限女生 https://www.douban.com/group/topic/113345605/
7号线_北艾路1200弄__正南温馨_干净安静:1690元(租女生) https://www.douban.com/group/topic/112014980/
7号线锦绣路站【山姆会员店】旁边 朝南精装大1室 带飘窗__2490元 https://www.douban.com/group/topic/111243092/
一三四八号线上海火车站附近 (2400)限一个女生 (实图个图)有厨房 朝南主卧 https://www.douban.com/group/topic/114856540/
一室一厅一厨一卫整租!7号线,上海大学地铁站!6分钟! https://www.douban.com/group/topic/114814137/
【无中介】2号线 中山公园和8号线翔殷路(靠近10号线五角广场)及9号线松江大学城站一室户 https://www.douban.com/group/topic/114031377/
七号线南陈路,整租两房两厅,便宜出租! https://www.douban.com/group/topic/113826619/
7号线__北艾路1200弄__超大一室,非常温馨:2490元 https://www.douban.com/group/topic/112276783/
2/4/6/9号线世纪大道站,精装双南两房一厅,6600元可谈,梅园五街坊 https://www.douban.com/group/topic/114883174/
这应该是徐家汇最好的公寓 https://www.douban.com/group/topic/113839494/
In [10]: keyword = '1号线'
In [11]: for tl in title_list:
...: if keyword in tl.a['title']:
...: print(tl.a['title'], tl.a['href'])
...:
1号线外环路站______主卧朝南、近地铁 https://www.douban.com/group/topic/115006334/
1号线❤️莲花路站❤️朝南+落地窗(4分钟到地铁)___2200¥ https://www.douban.com/group/topic/115010633/
1号线莲花路站_____步行2分钟(西班牙名园小区) https://www.douban.com/group/topic/115009200/
1号线❤️外环路站【主卧独卫】地铁口__ 上海阳城小区 https://www.douban.com/group/topic/115008659/
页码控制
以上海租房小组为例,之前测试爬取的路径是 https://www.douban.com/group/shanghaizufang/discussion 默认只会爬取第一页的 25 条信息,那么我们想爬取更多的信息,如何控制爬取的页码呢?

通过 class 属性为 next 的 span 标记可以获取到下一页的链接地址,https://www.douban.com/group/shanghaizufang/discussion?start=25 表示第二页从第 25 条记录开始展示,我们可以通过这个控制要爬取的信息条数。
代码概览
# -*- coding:utf-8 -*-
import os
import requests
import time
from bs4 import BeautifulSoup
class DouBanHouseSpider(object):
"""
抓取豆瓣小组房源信息
Attributes:
key_word: 房源标题关键字
page_num: 每个小组的抓取页数
group_list: 豆瓣小组列表
index_url: 豆瓣小组列表链接
data: 存放抓取结果
"""
def __init__(self, key_word, page_num):
self.key_word = key_word
self.page_num = page_num
self.group_list = ['shanghaizufang', 'homeatshanghai', '383972', 'shzf', '251101']
self.index_url = [os.path.join('https://www.douban.com/group', i, 'discussion') for i in self.group_list]
self.data = {}
print('豆瓣房源爬虫准备就绪, 开始爬取数据...')
def get_url_content(self, url):
"""
根据 url 抓取页面数据
Args:
url: 豆瓣小组链接
"""
try:
time.sleep(1)
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
title_list = soup('td', class_='title')
for tl in title_list:
if self.key_word in tl.a.attrs['title']:
self.data[tl.a.attrs['title']] = tl.a.attrs['href']
next_page = soup('span', class_='next')
if next_page:
next_url = next_page[0].link.attrs['href']
end_title = next_url.split('=')[1]
if int(end_title) < (self.page_num * 25):
self.get_url_content(next_url)
except Exception as e:
print('抓取过程报错:%s' % e)
def start_spider(self):
"""
爬虫入口
"""
for i in self.index_url:
self.get_url_content(i)
for k, v in self.data.items():
print('标题:%s, 链接地址:%s'%(k,v))
def main():
"""
主函数
"""
print("""
###############################
豆瓣房源小组爬虫
Author: Abnerzhao
Version: 0.0.1
Date: 2018-04-04
###############################
""")
key_word = input('请输入找房关键字:')
page_num = input('请输入抓取页面数:')
if not key_word:
key_word = '1号线'
if not page_num:
page_num = 5
house_spider = DouBanHouseSpider(key_word, int(page_num))
house_spider.start_spider()
print('豆瓣房源爬虫爬取结束...')
if __name__ == '__main__':
main()
请使用 Python3,爬虫源码地址
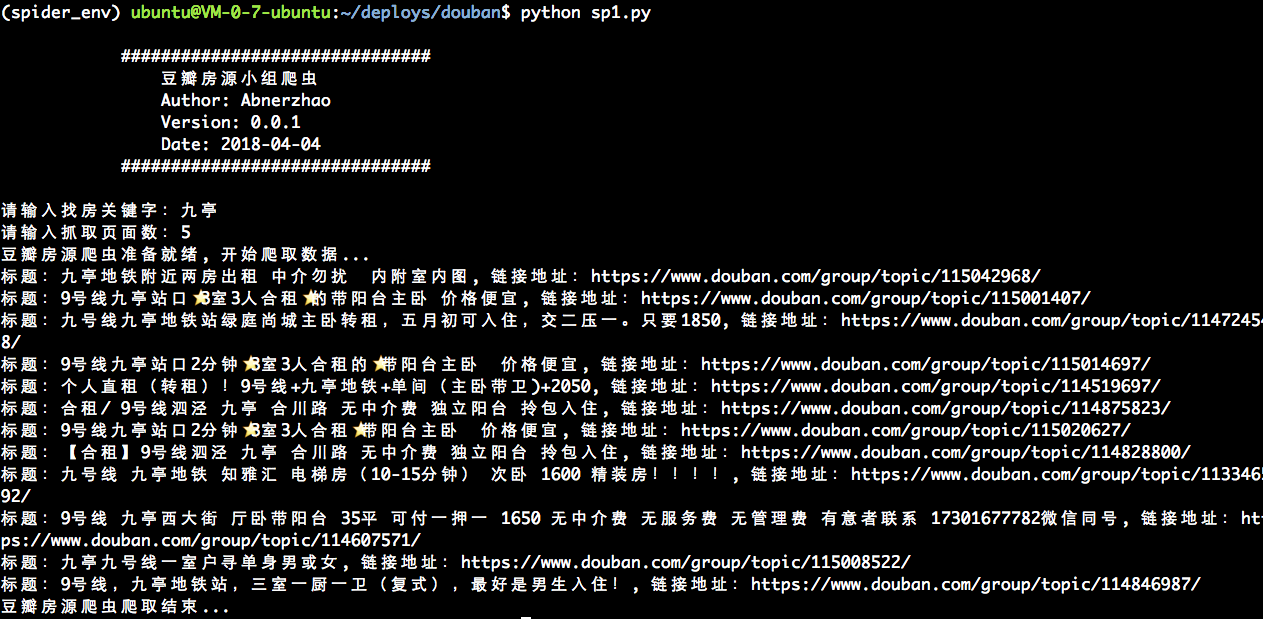
执行效果:
总结
这个爬虫很简单,没有进行模拟登陆也能抓取,当抓取页面数较大时会耗时较长。同一个房源信息可能在不同的小组中都有,所以通过一个字典来保存抓取的标题和链接,避免重复的标题。
后续待优化的地方:
- 模拟登陆
- 支持多个关键字
- 多线程